03 Jul 2025
Esattamente come la scorsa edizione è stata la mia prima presenza a openSUSE Asia Summit, quest’anno sono invece riuscito a incastrare, come avevo già scritto, l’avere un talk decente da portare con la mia prima openSUSE Conference. Di ritorno quindi, appunto, da openSUSE Conference ‘25 posso dire che queste conferenze quasi completamente verticali mi stanno piacendo sempre di più, e mi stanno facendo capire che se mi fosse reso conto prima del tipo di contenuto e del tipo di audience forse ci sarei venuto da molto molto tempo prima.
E la mia vita professionale forse avrebbe fatto giri diversi per giungere allo stesso punto.
Il posto
Non essendo mai stato alla openSUSE Conference, non sapevo che tipo di posto fosse lo Z-Bau finché non ci ho messo piede per la prima volta: è veramente incredibile, devo dire, vedere una conferenza incentrata sul software avvenire in un locale palesemente fatto per fare da centro sociale (e fin qua anche ok) e da posto per ospitare concerti anche di una certa dimensione e potenza. Non mancano infatti andando in giro per lo Z-Bau i poster di una fracca di concerti che spaziano dal goth al death metal al depressive black spinto, per non parlare di tutta la wave elettronica.
Anche se ora ho i capelli corti, da metallaro non ho potuto che apprezzare, anche perché la prima sera della conferenza nel cortile esterno c’era appunto un DJ set metal niente male. Grazie a questo tipo di location, per la prima volta ho tenuto un talk tecnico su un palco che era fatto per ospitare il metallo. Purtroppo non c’è stato nessun tentativo di pogo durante il momento del Q&A, ma non si può avere tutto dalla vita.
I talk
Togliamoci subito il dente: nella lineup degli speaker c’ero anche io con un talk su SchedKit, un progettino che ho iniziato a febbraio di quest’anno che si prepone di impacchettare in immagini OCI degli scheduler scritti per girare attraverso sched_ext, per poi avere del tooling che permette di prendere questi bundle OCI e far girare gli scheduler contenuti al loro interno. Il talk è andato bene, ci sono state anche un paio di domande interessanti; mi è dispiaciuto che alcune delle domande siano arrivate offline e non mentre c’era la registrazione che andava, perché sarebbe stato carino avere tutto il set di risposte da sbobinare.
A parte, appunto, il sottoscritto di cui ho parlato anche troppo, ho visto anche altri talk interessanti:
- Paolo Perego che ne ha portati addirittura due: uno sulla prototipazione di tool di security tramite gli LLM, e uno sull’importanza e sulle implicazioni dell’auditing del codice per gli sviluppatori di software open source. In particolare il secondo talk mi ha fatto riflettere sul fatto che nessuno dei miei progetti possiede un file SECURITY.md;
- Richard Brown col suo consueto aggiornamento su Aeon, dove siamo, dove andiamo e perché lo facciamo;
- Filippo Bonazzi con il suo workshop su openSUSEway, il “nostro” tentativo di fornire una rice di Sway bella e pronta con il branding di openSUSE e un po’ di cosette utili;
- Patrick Fitzgerald che ha cercato di fare un punto sull’adozione di Linux sul desktop attraverso progetti di migrazione strutturata (pubbliche amministrazioni and co.): l’aspetto interessante è che invece di fare un discorso filosofico Patrick ha anche portato dei numeri sui risparmi per i clienti e le opportunità di margine per i fornitori;
- Danilo Spinella che ha portato la sua ricerca sulle diverse strategie che adottano le distribuzioni Linux per quanto riguarda il packaging;
- Rick Spencer con la sua panoramica sullo stato della community di openSUSE: ho particolarmente apprezzato il fatto che in quanto General Manager della divisione Business Critical Linux di SUSE comunque non cerchi mai di forzare le cose all’interno del progetto open;
- Dan Čermák con un po’ di tooling per aggiornamenti del sistema operativo a partire da immagini OCI;
- Ish Sookun con due talk interessantissimi, uno sul mirror di openSUSE che hanno avviato nelle Mauritius (con un sacco di bash e nastro adesivo: ho apprezzato) e uno sul processo di approvazione delle membership di openSUSE, che è sostanzialmente un fardello enorme sulle spalle di pochi;
- Nico Krapp che ha parlato di come openSUSE stia supportando i Framework laptop.
C’è poco da girarci intorno: tra talk filosofici e talk tecnici devo dire che ho sbadigliato molto raramente in questi giorni, nonostante la mancanza di riposo dovuta essenzialmente ai litri e litri di birra bevuti coi miei colleghi e coi miei amici. Ho seguito talk veramente su qualsiasi argomento, senza filtro, facendomi un bagno di una cosa che adoro (i ~bratwurst~ sistemi operativi) senza soluzione di continuità per tre giorni di fila. Ma più di questo, la cosa che mi dà sempre maggiore soddisfazione è vedere di essere circondato da persone che pur con qualche divergenza di opinioni sono affascinate dal tema quanto me.
Ne parlavo con degli amici tempo fa: gli appassionati di queste tematiche sono veramente pochi e avere l’occasione di ritrovarsi di persona davanti a una birra è secondo me un tesoro da custodire - specie quando i tuoi amici sono così carini da portarti nei loro posti speciali. Come sempre è stata l’occasione per approfondire qualche conoscenza, per stringere nuove mani, ma soprattutto per sfondarsi di cibo tutti insieme durante il fantastico barbecue che lo staff della conferenza organizza più o meno ogni anno.
Tra il livello tecnico abbastanza alto e la compagnia, devo dire che mi piacerebbe fare di questa conferenza un appuntamento fisso. L’anno prossimo potrebbe essere un po’ più complicato, ma sicuramente quello dopo… :-)
Come nota di chiusura, verso la fine dell’evento ho avuto la mia grossa fettà di opportunità per parlare coi membri del board di openSUSE e fargli presente alcune cose che andrebbero riviste all’interno del progetto. In particolare:
- La creazione di gruppi di lavoro tematici intorno a specifiche aree, dato che spesso il lavoro è molto personalizzato e alla fine in mancanza di processi si tende ad avere delle “go-to people” che di fatto diventano silos
- Il fatto che il concetto stesso di membership e il processo di review debbano essere un pochino rivisti
Entrambe le proposte mi sono sembrate estremamente ben accolte. Per quanto riguarda i working group, ci si sta già lavorando. Per quanto riguarda la membership, Ish Sookun ha già detto che vuole metterci le mani e cercando lui volontari non mi sono certo tirato indietro.
Con queste premesse, sicuramente possiamo dire che fino a 2026 inoltrato sarò parecchio impegnato. See ya! Have a lot of fun!
15 Jun 2025
Tornando qualche settimana fa dal retreat a Barcellona di tutto il mio dipartimento sono stato sorpreso (almeno in prima battuta) dalla notizia che rimbalzava in giro per l’Internet secondo cui Mozilla avrebbe chiuso Pocket da Ottobre 2025. Oltre al fatto che io adoro Pocket come servizio, e che ero entusiasta di usarlo sia sui miei computer che su tutti i miei dispositivi dato che si integra (…va) nativamente con il Kobo, la reazione negativa che ho avuto nel leggere questa novità è stata accentuata ovviamente dal fatto che più o meno un anno fa ho deciso di svilupparne un client per il desktop Linux.
Oltre a rosicare tantissimo e a trovarmi inerme di fronte alla issue che mi ha aperto il buon Alessandro, chiaramente adesso mi sto chiedendo: che fare per il futuro?
RIP Pocket sul Kobo
Pocket sul Kobo era una figata. Secondo me avrebbero potuto raffinarne poco poco l’usabilità: per esempio la grandezza dei caratteri degli articoli di Pocket era stranamente molto piccola, e ogni volta che mi sono trovato a usare questa funzionalità ho dovuto aumentare la font-size talmente tanto che andando poi a rileggere un libro sembravo uno di quegli orbi che leggono due lettere per pagina.
Tutto sommato, non una sorpresa
Stupido io ad investirci così tanto: Pocket sembrava già alla canna del gas da tantissimo tempo, e ho deciso di ignorare tutti i segnali. Primo tra tutti, proprio il segnale principe di non mantenere più e addirittura togliere dall’App Store il client per Mac, che era un piccolo gioiello.
Quantomeno mi rimane la soddisfazione di essere stato capace di replicare quell’esperienza utente prima della fine.
Gli altri segnali sono sempre stati un reiterato tentativo di palesare il fatto che Mozilla non era assolutamente interessata a continuare il lavoro su Pocket, specie avendo realizzato di non poterci guadagnare. Insomma, non voglio buttarla troppo sul politico, ma un’altra grande vittoria del capitalismo - e a rimetterci siamo sempre noi consumatori, dato che all’interno di un sistema capitalista parlare di utenti anziché di consumatori secondo me mistifica e altera un pochettino la percezione della realtà.
Le alternative (self-hosted) che ho valutato sono Wallabag e Shiori: ho tentato di non farmi contaminare troppo dai dettagli implementativi, ma il fatto che Wallabag, pur ricco di integrazioni, sia in PHP mi rende veramente difficile pensare che sia facile da operare e con poco impatto sulla mia infrastruttura, che è piccolina.
Gli impatti su Cauldron
Non ultima ovviamente per me la domanda cardine: cosa succederà a Cauldron?
Per Cauldron vedo alcune vie, soprattutto data la presenza per Wallabag di un client desktop:
- Buttarlo nel secchio (è una possibilità);
- Convertire l’applicazione a un approccio multi-provider che permetta di autenticarsi con qualsiasi servizio;
- Convertire l’applicazione in un client desktop per Shiori.
Tutto questo (qualsiasi cosa non rientri nella decisione del secchio) sarebbe comunque fattibile per me solo nella seconda metà inoltrata dell’anno.
Per una volta che avevo fatto una cosa carina… ma vabbeh, shit happens :-)
02 Jun 2025
Poco dopo il FOSDEM di quest’anno mi sono messo a ragionare se avesse senso tentare di eseguire scheduler scritti con sched_ext in maniera containerizzata. La parola “containerizzato” per uno scheduler userspace è abbastanza stiracchiata semplicemente perché comunque il processo all’interno del container ha comunque bisogno di privilegi più elevati rispetto a quelli usuali, rompendo un po’ il modo di pensare classico rispetto a queste tematiche.
Prima di spenderci troppi pensieri, avevo già creato un piccolo tool che sostanzialmente si interfaccia in maniera abbastanza “opinionata” a containerd e Podman e li usa come container engine/runtime per istanziare uno scheduler containerizzato scritto usando appunto sched_ext, che permette di implementare scheduler personalizzati attraverso una serie di callback tramite eBPF.
La notizia in realtà non è tanto questa, quanto il fatto che a fine Giugno sarò a Norimberga per la openSUSE Conference 2025, per parlare appunto di schedkit, dei traguardi che ha raggiunto e delle prossime mosse. È la prima volta che presento un progetto così ambizioso, e devo dire che non pensavo nemmeno che mi accettassero il talk :-)
Ho una nuvola di cose in testa in questo momento anche perché sono reduce dal retreat del mio team a Lisbona qualche settimana fa, ma non volevo che un annuncio del genere alla fine andasse perso semplicemente per pigrizia. Stanno succedendo parecchie cose in queste settimane, sia lavorativamente parlando che personalmente parlando, e spero che questo blocco note non patisca ancora a lungo.
Ci vediamo alla openSUSE Conference!
20 Mar 2025
Pur essendo una persona che soffre moderatamente il cambio di stagione, devo dire che sto accusando quest’entrata della primavera in maniera meno grave del solito, e uno dei motivi è che il design team di GNOME (nella persona di Brage Fuglseth) ha finalmente dato un’icona a Cauldron. Sinceramente sono sempre stato emozionato più del dovuto per questa cosa, e devo dire che fin dal primo momento mi sono eccitato come un cucciolo di labrador perché non solo ho provato a fare un’app desktop e ci sono sommariamente riuscito, ma grazie a questa icona adesso sembra anche una “cosa vera” - di quelle del desktop environment per davvero, ecco.
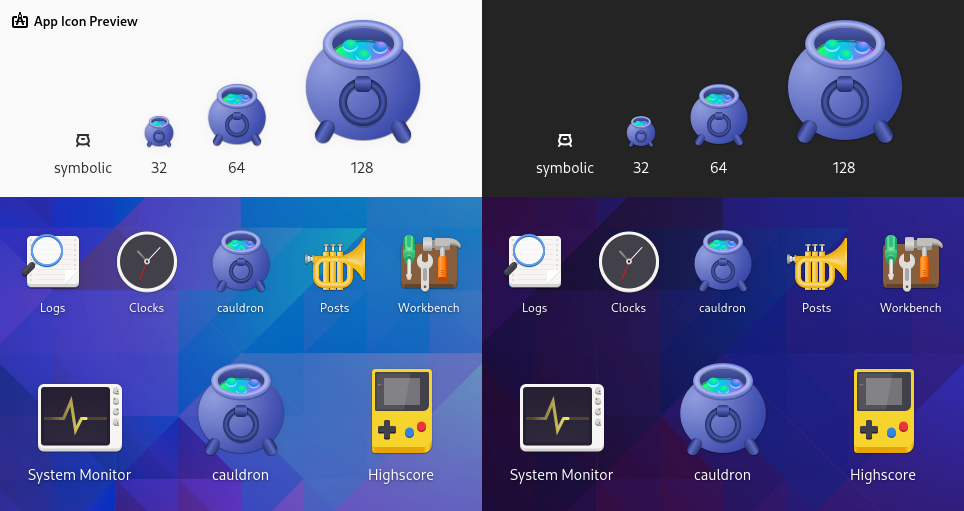
Questo mi ha dato un boost di motivazione per aggiungere due cose che volevo piazzare dentro Cauldron da tantissimo tempo:
- Copia nella clipboard: ovvero, appunto, un pulsante per copiare nella clipboard l’URL del post che si sta visualizzando;
- Apri nel browser: un altro pulsante che apre nel browser di default l’articolo che si sta visualizzando.
Sono due cose che ho sempre avuto a disposizione in tutti gli RSS reader per ogni piattaforma, ovviamente a partire dal mitico Newsflash, e dato che erano tutto sommato delle vittorie facili non vedo perché farcele mancare. Anche perché, appunto, Pocket for Mac, da cui ho preso spunto, ce le ha entrambe e sono comodissime.
Godetevi tutto!
16 Feb 2025
Dato che ormai è parecchio tempo che contribuisco a openSUSE in maniera attiva (principalmente mantenendo aggiornato insieme a un manipolo di bravi il pacchetto di Elixir) ho trovato il coraggio e il tempo di sottopormi al processo di assegnazione della membership all’interno del progetto.
Lo status di membro è una cosa incognita, e ne sto appunto parlando perché rispetto alle decine (se non centinaia) di persone che ogni giorno inviano patch e documentazione secondo me non gli viene data abbastanza attenzione. Innanzi tutto se siete interessati a contribuire a una distribuzione Linux vi consiglio di leggere la pagina wiki associata.
Dopodiché, nel mio caso è andato tutto molto bene dato che ho partecipato parlando di openSUSE a varie iniziative e conferenze, oltre al codice. Se siete italiani e avete contribuito in maniera costante e misurabile vi consiglio di richiedere la membership perché così almeno potete:
- Sfoggiare l’IRC cloak (se siete anziani)
- Sfoggiare l’indirizzo email
@opensuse.org
- Essere su Planet SUSE
- Partecipare alle elezioni del board
- Essere eletti nel board
In realtà le funzioni del board di openSUSE sono parecchio limitate, si tratta per lo più di organizzazione ad alto livello, ma se volete avere un impatto maggiore è sicuramente una cosa da prendere in considerazione. In particolare negli ultimi tempi ho avuto modo di constatare che, appunto, lo status di openSUSE Member è qualcosa di abbastanza misconosciuto.
Dopo di me è stato anche accolto a braccia apertissime il buon Paolo che, io non lo sapevo, è maintainer della ZSH che uso tutti i giorni su tutti i miei setup, quindi ne aveva molto più diritto di me :-D